“Deep Researchの中の人”を手動でやってみる
はじめに:Deep Researchの衝撃
先日、ChatGPTの「Deep Research」という機能がProユーザー向けに提供されました。 Deep Researchは、オンライン上の情報ソースからデータを検索し、詳細なレポートを作成してくれる「リサーチエージェント(アシスタント)」と呼ばれるものです。
実は、ChatGPTに先駆けてGoogleのGeminiにも同名の機能が存在していたり*1、Perplexity AIにも検索結果と応答から詳細なレポートを生成する機能がすでに提供されていました*2。 さらにさかのぼると、LangChainユーザーの間ではGPT Researcherという類似のツールとして知られているかもしれません。 私自身は『その仕事、AIエージェントがやっておきました。』という本を通じて、このようなリサーチエージェントの存在を知りました。

最近Gemini Advancedのユーザーからも「Deep Researchがいかに強力か」という評判を聞いていましたが、実際に自分でChatGPT版に触れてみて、その意味を実感できました(念のために書くと生成されたレポートはネットで検索できる範囲についてかなりの精度を発揮しますが、ウェブ検索結果より自分のが詳しい分野だとそれほどあてにはならない印象です)。 Deep Researchリリース後は世間でも「数時間かかる一流コンサルレベルの作業が一瞬で終わる」とか「このような機能が、今後ネット社会をどう変えていくのか」というビジョンを語る人が増えています。 そんな中、私はひとしきり遊んだ末に「これって、いったいどうやって作られているんだろう?」という技術的な背景に関心を持ち、関連情報を集め始めていました。
多数のDeep Researchクローンの登場
ChatGPTのDeep Researchが大きな話題となる中、そのコンセプトを再現したクローンが次々と登場しています。 たとえば、Firecrawlの創業者による「Open Deep Research」や、Hugging Faceのsmolagents開発チームが手がけるデモ実装*3がよく知られています。 さらに、LangChainの「ollama-deep-researcher」やJina AIの「node-DeepResearch」「dzhng/deep-research」といったプロジェクトも存在します。
 (Open Deep ResearchはUIも作り込んであります。すごい)
(Open Deep ResearchはUIも作り込んであります。すごい)
これらDeep Researchクローンのオープンソース実装を調べてみたところ、内部で行われている処理の全体像がおおむね把握できたため、「自分もこれでDeep Researchの一員としてやっていけそうだな(!)」と感じました。 つまりその気になれば、エージェントを自力で開発しなくてもノンプログラマーがブラウザベースの手動運用でこれが模倣できるんじゃないのか? という段階まで来ました。 Deep Researchは月額200ドルのChatGPT Proユーザー限定機能であるため、まだ多くの人が試せていない状況かもしれません。 そこで今回は、「Deep Researchクローンの処理を実際に手動で追体験する」ことで、Deep Researchを疑似体験してみようと思います。
工程1:ユーザーの依頼からウェブ検索クエリを作成する
まず、私たちの「私家版Deep Research」のユーザーから「2024年における企業のAIエージェントの活用実績と問題点を調査してほしい」というオーダーが入ったとします。 この依頼についてウェブ検索を実施するために、どのようなキーワードを使えばよいかをAIに考えてもらいます。
ここで活躍するのが「Google AI Studio」というサービスです。長文レポートを格安で作成でき、AIモデルとしてGeminiが応答してくれます。先日Gemini 2.0 のアップデートがきたばかりなので*4腕試しにもちょうどよいでしょう。”Gemini 2.0 Flash”というモデルを選択します。
実際には、以下のように入力してキーワードをリストアップしてもらうイメージです。
「2024年における企業のAIエージェントの活用実績と問題点を調査してほしい」 これを調査するためのウェブ検索クエリをリストアップしてください。
すると、30個もの検索クエリ候補が返ってきました(!?)。

しかし、あまりに多いので面倒になり、一番広く検索できそうな「2024年 AIエージェント 企業 活用状況」だけを選んで採用することにします。
工程2:ウェブ検索結果を一括ダウンロードしてくる
まずは作成したウェブ検索クエリを使って、情報源となるWebページを調べます。 ヒットしたWebページの内容を次の工程へ渡す必要がありますが、Google検索にキーワードを入力し、一件ずつ内容を取得していては日が暮れてしまいます。 そこでウェブ検索代行サービスを活用するのがおすすめです。
Jina AI Readerは「URLを受け取り、そのコンテンツを取得するAPI」を提供していますが、最近では「検索クエリを受け取り、バックエンドで検索して結果を返すAPI」も利用できるようになりました。 他にもTavily、SerpApi、Perplexity API、Firecrawl Searchなどがありますが*5、それぞれ「検索結果のページリストを取得できるか」「ページのコンテンツまで取得できるか」といった点で差があります。 一つひとつ手動でページを開いて内容をコピーするのは大変なので、今回はJina Readerを使うことにしました。
Jina AI へサインアップ後、APIコンソールで「検索クエリモード(Use s.jina.ai to search a query)」に切り替えて、先ほどのクエリ「2024年 AIエージェント 企業 活用状況」を入力します。
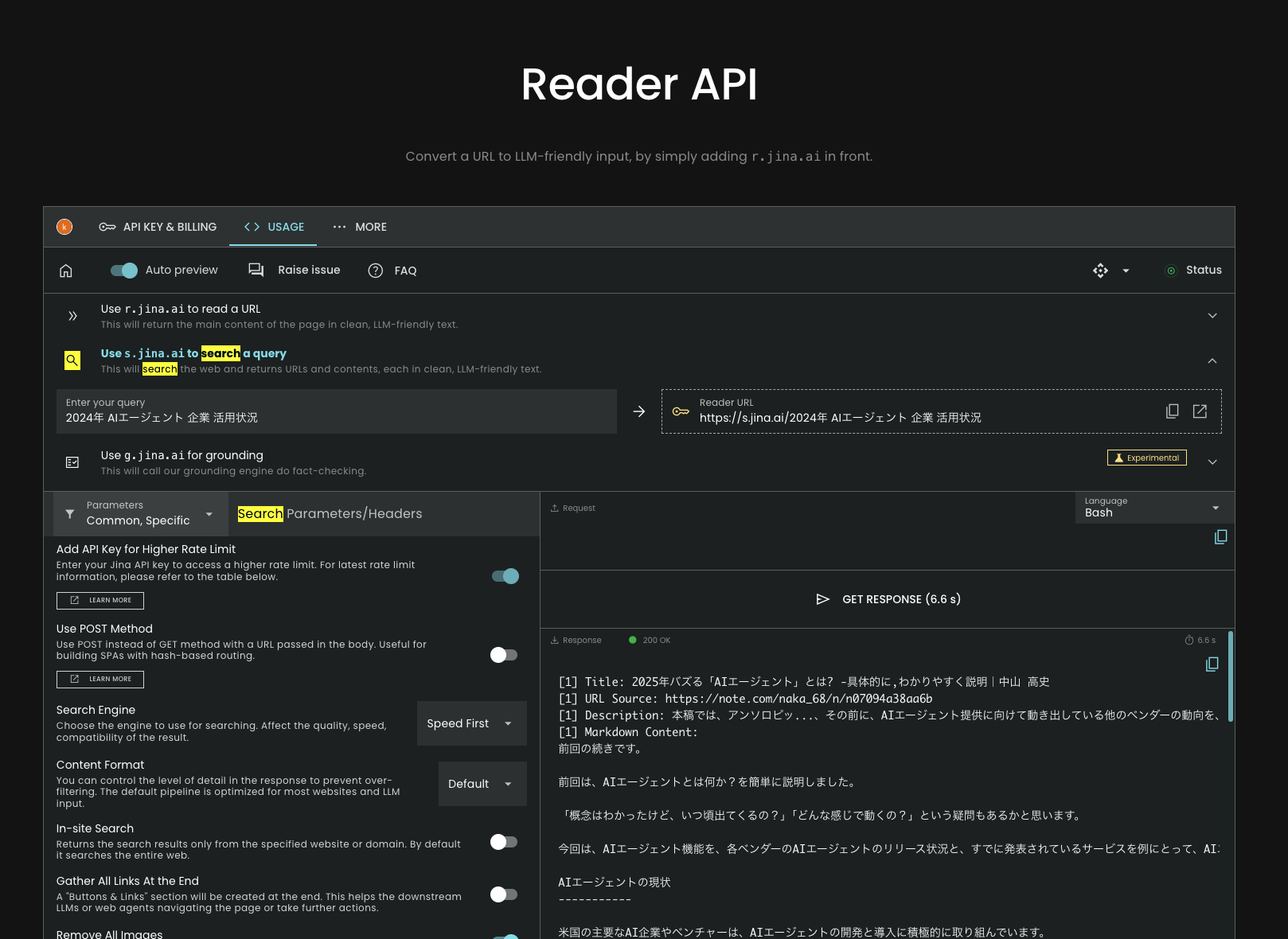
「GET RESPONSE」ボタンを押すと結果が表示されますので、それをメモ帳などにコピーし、「result.md」というファイル名で保存しておきましょう。
工程3:ウェブ検索結果を使ってレポートを作成する
次の段階では、先ほどの検索結果を使ってレポートを作成します。 具体的には、Google AI Studioに戻り、取得したファイルを添付したうえで、次のような指示を送信します。
「2024年における企業のAIエージェントの活用実績と問題点を調査してほしい。 このレポートを以下のウェブ検索結果を使って作成してください。」

すると、自動生成されたレポートを確認できるのですが、読み返してみると「どうにも浅い…」と感じてしまいました。 機械的に整理した表面的な情報だけが並んでしまい、物足りなさを感じます。 そこで、より深みのあるレポートにするために、次の工程で改善を図っていきましょう。
工程4:検索クエリを変えてみる
「工程1:ユーザーの依頼からウェブ検索クエリを作成する」で29個の検索クエリを捨てていたことを思い出しました。 これらを再び活用しながら「工程2:ウェブ検索結果を一括ダウンロードしてくる」をやり直すことにします。
今回、レポートには「エージェント活用における問題点」の分析が足りなかったと感じたため、「AIエージェント 導入失敗 企業 2024」という、やや露骨なキーワードを新たに選択しました。 これによって得られた検索結果を再度「result.md」として保存します。
さらに、「工程3:ウェブ検索結果を使ってレポートを作成する」で作成したいまひとつのレポートは「report.md」として別途保管しておきましょう。
工程5:追加情報でレポートを改善!
今度はGoogle AI Studioに戻り、「既存の作成済みレポート(report.md)」と「新しく取得した検索結果(result.md)」の2つのファイルを添付したうえで、下記のように依頼します。
「2024年における企業のAIエージェントの活用実績と問題点を調査してほしい。 このレポート(report.md)を、追加情報(result.md)を使って改善してください。」

※補足:「工程3:ウェブ検索結果を使ってレポートを作成する」で使った会話スレッドはそのままにして、新規で会話を開始するほうが良いでしょう。Geminiが扱うコンテキストを狭めて集中力を発揮してもらうためです。
これで新しいレポートが完成しました。さあ新しいレポートが作成されました。読んでみましょう。 まだ物足りない? う〜ん、責任転嫁するのはよくないのですがユーザーさんがふわっとした依頼をするのも悪いんじゃないですかね? 最終的にクライアントの意図に合ったレポートを仕上げるには、分析したいことを明確にするためにクライアントにヒアリングをしましょう!
 (これはChatGPTも行なっていることです)
(これはChatGPTも行なっていることです)
工程6:レポートの対象を明確にしよう!
そこでチャット受付窓口に戻り、ユーザーさんに「どんなレポートが必要なのか」を聞き返してみましょう。以下のようなプロンプトを使って得られた回答を、そのまま丸投げします。
「2024年における企業のAIエージェントの活用実績と問題点を調査してほしい」 このレポートを改善するために、どういう観点で詳細化するべきか逆質問をしてください。
聞き返した結果、ユーザーから「うーん、金融業界で大企業の営業職とか?」というキーワードが得られたとします。そうしたら「工程1:ユーザーの依頼からウェブ検索クエリを作成する」を繰り返します。
めんどくさいので、そのままコピペしましょう。
「2024年における企業のAIエージェントの活用実績と問題点を調査してほしい。うーん、金融業界で大企業の営業職とか?」 これを調査するためのウェブ検索クエリをリストアップしてください。
すると、新たに「2024年 金融業界 AIエージェント 営業活用」というクエリが取得できました。
この後は「工程3:ウェブ検索結果を使ってレポートを作成する」に移行し、ひたすら全肯定を繰り返すだけです。
規定の回数を繰り返して納得のいくレポートが作れたら、あとは納品するだけ。
工程7:さあ納品だ。仕上げは大先生
そのままユーザーへ結果を報告してもいいのですが、最後だけ特別にGemini 2.0 Pro Experimental*6という一番強力なモデルを変えて、レポートを仕上げてみましょう。
今までかき集めた情報をアップロード可能な限り全て含めて以下のように入力します
「2024年における企業のAIエージェントの活用実績と問題点を調査してほしい」 以下の情報を統合してレポート(report.md)を改善してください。
以上で、レポートの仕上げが完了です。お疲れさまでした。
参考としてこの方法で作成したレポートをアップロードしておきました。
2つを比べてみるとやはりOpenAI版のが重厚というか、情報量に優ります。単純な文字数も倍近く多いです。 これはAI Studioが出力できる文量が限られている(8192トークン、5千文字程度)のと、私が入力した検索結果データ(result.md)のボリュームが少ないからというのがまず思い当たります。 またOpenAIはDeep Research用にトレーニングしたo3モデルを使っているので単純なモデルの差もあるでしょう。 その意味で既存のAPIを使ったオープンソースのクローンアプリでできるレポートはOpenAI版と同等の成果物は得られません(Gemini版も内部が分からないので不明)。 そもそもDeep Research の定義自体が定まっていないので極端な話「検索結果のサマリを5分待ってから表示する」だけでも人間がDeep Research だと認識すればそう言い張れてしまいます。
おわりに
以上、Deep Researchのオペレーションについて簡単に解説してみました。
おさらいすると以下の工程を自動化して高度に自動化できるとDeep Research風のエージェントが作れます
- ユーザーの質問から検索クエリを生成する
- 検索クエリで得られたWebページのコンテンツを収集する
- Webページのコンテンツを知識として統合して仮レポートを作成する
- 仮レポートを自身で評価して検索クエリ→知識の更新(や要約で折りたたむ)→レポートの反映を繰り返す
- 最後に全体をまとめる
これで皆さんも「Deep Research店」を開業できるかもしれません。
ただし、これはOpenAIが公開している情報ではなく、クローンアプリやオープンソースのエージェントから得た情報を私なりに単純化して説明したものです。 実際のソースコードでは状態の保持やプロンプトの差し込みなどはもう少し複雑なことが行われています。 例えば、一部のクローン実装にあるプロンプトは結果を再帰的に評価してモデル自身に思考させるフローもあります。 それをこの記事では人間側で済ませてスキップしています。 OpenAI版のDeep Researchの挙動からは1つ1つのページを読み込んで思考した記録も推論に使用していると思われます。 また、この作業には大量の文章を取り扱うこともあってAI StudioやGemini APIを利用する際の費用などは事前にご自身でも確認するようにしてください。
*1:Gemini: Try Deep Research and Gemini 2.0 Flash Experimental
*3:Open-source DeepResearch – Freeing our search agents
*4:Gemini 2.0 model updates: 2.0 Flash, Flash-Lite, Pro Experimental
*5:Firecrawl Searchは厳密にはベータ版の他のサービスのラッパーで、現在のバージョンv0からv1の時にしれっとドキュメントかた消えていました。いつまで提供されるか不明。
*6:Access the latest 2.0 experimental models in the Gemini app.